
GLB文件
撰写时间:2024-01-24
修订时间:2024-01-25
何为GLB
基于base64编码的Data URL虽然可以将二进制数据转换为内嵌的格式,但导致了编码所需空间比未编码的资源增大了约33%。且解码也需要时间。
为解决上述这两个问题,一种完全使用二进制的.gltf文件应运而生。它称为Binary glTF(二进制 glTF)。二进制 glTF可将代表.gltf文件的JSON文件, 连同buffers, 图像等资源一起,都打包进一个单独的文件。同时,它也可以引用外部资源。
文件格式
二进制 gltf文件的文件扩展名为.glb。其结构如下图所示:

具体来说,它具有如下结构:
- 一个12个字节的头部(header)
- 一或多个包含JSON及二进制数据的区域(chunks)
在上面的图像中,该文件包含了1个头部及2个区域。第1个区域是JSON格式的.gltf文件的内容,也称为JSON chunk,它必须放在所有其他区域的前面。第2个区域称为二进制缓冲区(binary buffer),也称为bin chunk,用以存放诸如图像、基本图元、动画关键帧、皮肤等以二进制形式存储的资源。根据需要,可以有0或1个bin chunks。
明白了此结构,我们可以从.glb文件中提取数据了。
下面,我们以Box.glb文件为例子,逐步分析并提取其相应数据。
显示:
上面的代码,加载Box.glb文件,将其内容解析为ArrayBuffer类,并打印该类。
后面的1664
表示该文件大小为1664
个字节。在操作系统中对该文件按右键,选属性
,可看到该文件的大小。这两个数值是完全一致的。
现在,我们开始玩字节游戏了。
Header
根据上图,header部分共有12个字节,又分为magic
,version
,length
3个部分。每个部分的类型均为Unsinged Int 32,字长为4字节,对应于JavaScript的Uint32Array。
Magic
先根据第一个magic
部分的类型,取出相应的字节。
上面代码,从arrayBuffer中,从第0个字节开始,取出1个Uint32Array的数据。因为Uint32Array的字长为4,因此共取出了4个字节。下面打印magic的各个属性:
显示:
buffer属性表明其数据的来源,byteLength表示该变量的字长,byteOffset表示数据在buffer所指定的ArrayBuffer中所处的偏移值,length表示该变量作为数组所拥有的元素数量。
注意,Uint32Array是一个数组,因此,即使我们只取出一个这样的数据,其结果也将保存在数组的第1个元素中。因此,我们这样查看其具体数据:
出现了一个很大的数字1179937895
。这个数字代表什么?我们看一下其十六进制的值:
GLTF 2.0规范中指出,magic必须等于0x46546C67
,它是字符串glTF
的ASCII值,用以标识数据类型为二进制glTF。
数值对上了。我们想看一下是否真的如此。
在以十六进制表示的形式中,共有0x46
, 0x54
, 0x6C
, 及0x67
4个字节。
顺序相反了。这是典型的大尾小尾的问题。Bin glTF采用小尾格式(little endian),所以在存储多字节时,是从右到左的顺序来存储。
上面的查看方法不仅需要逐个字节分开打印查看,并且顺序还相反,很不方便。我们可以使用TextDecoder类来查看。
显示:
TextDecoder的decode方法将参数中的类型化数组转换为字符串,非常吻合我们需要跟类型化数组打交道的场合。并且,它自动解决了大小尾的问题。
小结:对于以ASCII值存储在类型化数组的数据,可借助TextDecoder类来方便地转换为默认的UTF-8字符串。
我们如何知道类型化数组存储了ASCII值?GLTF 2.0规范要求magic必须如此。
Chrome中查看二进制数据
Chrome浏览器的开发者工具可以很方便地查看二进制数据。对于下面的代码:
在Chrome的开发者工具中,可看到如下的图像:
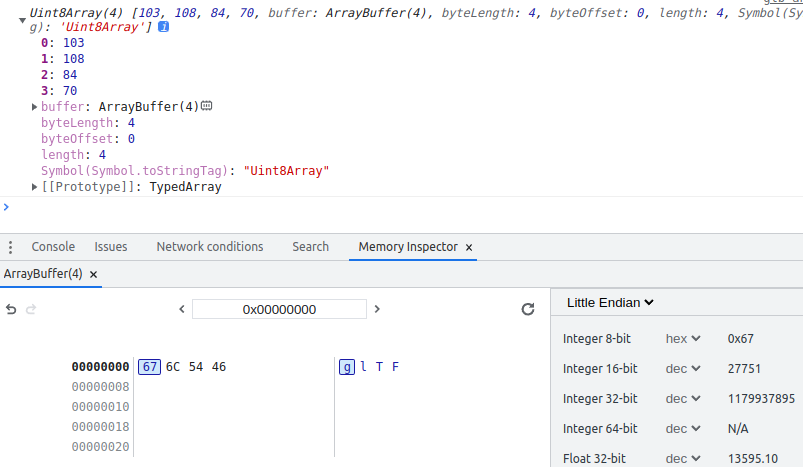
点击buffer属性值ArrayBuffer(4)
旁边的小图标,可看到上图中最下面的部分。在左边面板中,左列为地址,中间列为类型化数组的4个元素以十六进制来显示的ASCII值,右边是对应的字符。
我们发现,对于同一个缓冲区,如果以Uint32Array来取出4个字节,则它以小尾格式排列。而如果以Uint8Array来取出4个字节,它自动恢复了正常的顺序。在我们创建Uint8Array的实例时,系统在内部已经按正确的顺序读取数据。
也就是说,如果我们以单字节的Uint8Array之外的类型化数组从ArrayBuffer中取出数据时,应将它们视为一个整体,不要擅自人为的拆分解读。若一定要人为拆分,必须考虑大小尾问题。或者,使用上节中的TextDecoder类,让其帮我们按内部的存储顺序正确解读。
Chrome的开发者工具可以很方便地查看类型化数组中buffer属性所指向的ArrayBuffer。这意味着当我们希望通过Chrome的开发者工具来查看特定区域的内存时,第一步是先确定要查看的ArrayBuffer的区域,如上面:
arrayBuffer很大,但上面只取出4个字节。第二步,使用这个subArrBuf来创建类型化数组的实例,如:
这样便可做到精准筛选。否则,若所选取的区域很大,则很容易迷失。试着用下面的代码来查看内存区域:
整个arrayBuffer共有1664个字节,显得太杂了。
Version
下面代码取出header部分的第2个Unsigned Int 32的数据,也即version的数据:
这里也同样存在大小尾问题。但由于我们知道代表版本号的数值是一个整数,因此没必要去人为地拆分它,直接打印该类型化数组中第0个元素值即可。
在Uint32Array的构造方法中,第2个参数为偏移值,以字节为单位,即需要偏移多少个字节?前面已存储了一个Unsigned Int 32的数据,占去了4个字节,因此这一步需从第5个字节开始(元素索引值从0开始记,这里索引值为4)。
Length
header中的length部分存储了整个.glb文件的总长度。
至此,整个header部分已经解析完毕。下面将解析chunks。
Chunk 0
可能有1个以上的chunks,而第1个chunk是必须有的。我们将其称为chunk 0。
每个chunk的格式也是固定的。共分为chunkLength, chunkType及chunkData3部分。
chunkLength
chunkLength指明本chunk中存储数据的chunkData的字节总长度,其数据类型为Unsigned Int 32。因此,当前指针已来到第3个该类型的位置了。
说明本chunk的chunkData的字长为988个字节。
chunkType
chunkType指明本chunk的类型,其数据类型为Unsigned Int 32。其值只有固定的2种:
- 0x4E4F534A: JSON
- 0x004E4942: BIN
可能还会有其他类型的chunk,但这些都是为将来扩展而准备的,如果遇到这些类型的chunk,应当予以忽略。
0x4E4F534A
正是字符串JSON
的ASCII值序列。表明本chunk是我们之前所学过的.gltf文件的内容,以JSON的形式来编码。
chunkData
chunkData是本chunk所存储的数据,其数据类型为Unsigned Byte。
前面的chunkLength已经告诉我们这个chunkData的具体字节长度,现在,只要我们根据当前偏移值就可取出其全部数据。
此时,chunk0Data仍是ArryBuffer的一片子区域。由于它是使用JSON字符串所编码的数据,因此,我们需要依下面两步进一步处理。
第一步,根据上面所学,使用TextDecoder来解码为字符串:
第二步,使用JSON类来进行解析:
我们得到了之前非常熟悉的glTFObj对象。但与之前相比,还是有一个细微区别。
显示:
而原来的Box.gltf文件的buffers属性是:
两相对比,前者缺失了uri属性。
这就是.glb文件中buffers比较特殊的地方。我们之前说过,.glb文件可有0或1个bin buffer。如果有bin buffer,它可以将二进制数据放在此buffer中而在文件内部予以引用。这个bin buffer就是图中的chunk 1。
GLTF 2.0规范这样声明:如果存在chunk 1,则必须满足这两个条件:
- 它必须由.glb文件的buffers中第0个buffer引用。
- 第0个buffer不能带有uri属性。
其后的buffer则可自由引用外部的二进制资源。
因此,上面没有uri的第0个buffer,说明Box.glb文件存在chunk 1部分,且被引用了。
Chunk 1
根据上面所学,不难得出chunk 1的各个属性值。
它的字节长度为648
个字节,其类型为BIN
,最后的chunk1Data则存储了chunk 1的数据。
至此,我们解析并提取出了Box.glb的所有数据。
加载并显示.glb文件
实现GLBLoader类
在这一节,我们利用上面所学知识,实现一个GLBLoader类。
类实例变量glTFObj是我们加载文件后要返回的对象,arrayBuffer是整个二进制缓冲区。依照规范,我们使用header, chunk0及chunk1这3个实例变量来分别存储相应的数据。
loadFile方法是供客户端调用的总入口。在加载.glb文件后,我们将其二进制数据直接赋值于实例变量arrayBuffer。然后分别处理.glb文件的3个部分,最后向客户端返回glTFObj。
下面是initHeader方法:
因为头部的总长度是固定的,因此我们先取出这一部分缓冲区数据,以供magic, version及length变量使用。这3个变量均分别存储为实例变量header的3个属性。
header的bytesNum属性还存储了头部的总字节数,这样后面的代码从arrayBuffer中读取数据时就可以很方便地确定偏移位置。
下面是initChunk0方法:
因为chunk0的data属性存储了JSON格式的ASCII值,我们将此缓冲区数据直接转换为glTFObj。同样,chunk0的bytesNum也存储了当前部分的总字节长度。
下面是initChunk1方法:
因为不是每个.glb文件都有chunk1部分,因此,我们先根据glTFObj的第0个buffer是否有uri属性来作出判断。
chunk1的data属性中的值仍保留为ArrayBuffer的形式,因为glTFObj在以后才能决定如何使用它。又因为它是glb容器内的缓冲区,我们将其存进glTFObj的glbStoredBuffer属性,以供将来glTFObj方便调用。
为GLTFLoader添加处理.glb文件的功能
我们将GLBLoader类放在之前的GLTFLoader类内使用,这样可保持向下兼容,客户端代码除了引用新版的GLTFLoader类外,其他部分无需改变。
新旧版的GLTFLoader的loadFile方法,只要返回glTFObj就行。
glTFLoader-v2.0.js只需改动两个地方。首先是loadFile方法:
如果是.glb文件,则由GLBLoader类负责加载并解析,否则,使用原版的加载并解析功能。
第二个需改动的地方是loadBufferData方法:
如果参数buffer有uri属性,则调用之前的代码;否则,直接从glTFObj的glbStoredBuffer属性提取即可。
运行应用。